欢迎光临 宁波利来国国际APP,利来囯际老牌,利来囯际网址电子股份有限公司!
宁波利来国国际APP,利来囯际老牌,利来囯际网址电子股份有限公司!



今日股价


DeepSeek震撼全球英伟达股价暴跌1697%AI领域中国的一席之地。
发布时间:
2025-02-19
1月26日★★★,游戏科学创始人★★、CEO,《黑神话★★:悟空》制作人冯骥评价DeepSeek★★:可能是个国运级别的科技成果。


在硅谷,DeepSeek很早就被称作“来自东方的神秘力量”,也是网上热议的★“杭州六小龙★★★”之一★★★。

这场科技股的“地震”,不仅让投资者对AI的获利能力以及尖端芯片的旺盛需求感到担忧,也引发了市场对传统科技巨头未来地位的重新审视。

DeepSeek非常偏爱没有工作经验的年轻人★★★,而且指明不要资深人士,“工作经验在3~5年已经是最多的了,工作超8年的基本就pass了”★★。
DeepSeek的横空出世,凭借其低成本★★、高性能的AI模型,迅速在国际舞台上崭露头角。其最新发布的AI模型DeepSeek R1,通过结构化稀疏注意力★★、混合专家系统等技术优化★,显著降低了模型训练和推理的算力消耗。
随后★,在本月世界经济论坛2025年年会开幕当天,中国深度求索公司发布其最新开源模型R1★★★,再次引发全球人工智能领域关注。
DeepSeek百余人的规模显得相当精炼★,并且在选人标准上两者也大有不同★,互联网公司一般看重成熟的经验★★★,最好有在核心项目成功过的经历,而DeepSeek则喜欢“高潜力年轻人”★★★。
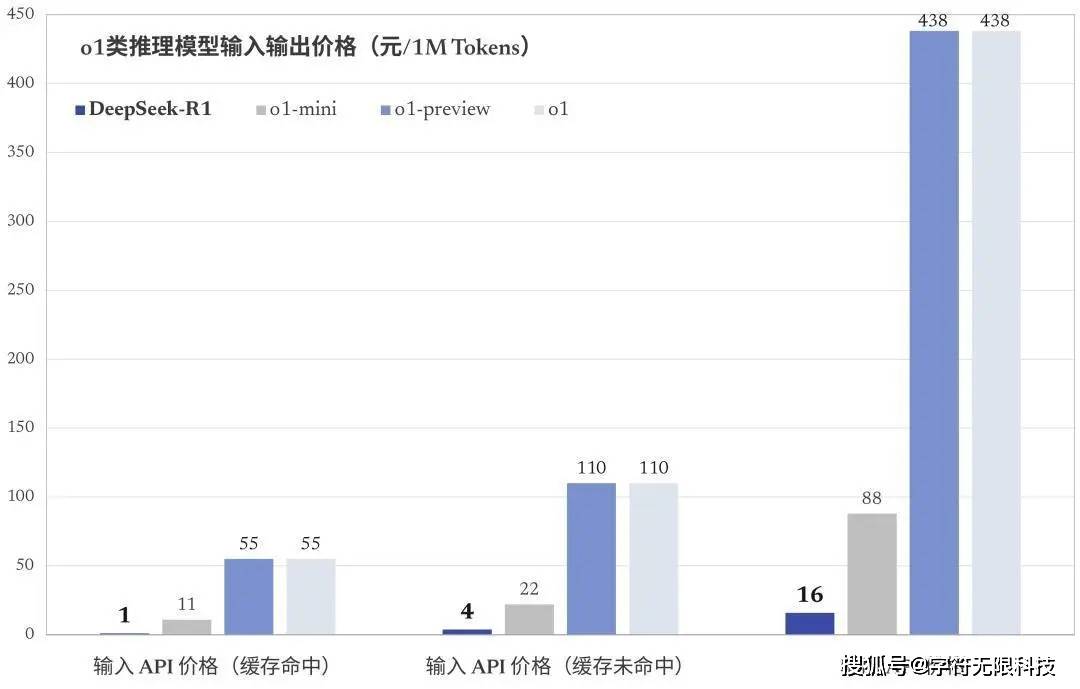
与传统依赖高算力芯片堆叠的AI训练方式不同,DeepSeek R1的训练成本仅为OpenAI同类模型的1/30。
DeepSeek的技术突破,预示着算力军备竞赛的终结。长期以来★,美国的AI霸权建立在高算力和高资本投入的基础上,英伟达等芯片巨头以GPU为核心构筑的生态系统在其中扮演了关键角色。

据了解★★★,在团队配置上,DeepSeek团队只有139名研发人员,对比ChatGPT的OpenAI团队则有1200名研究人员★★,团队规模是DeepSeek的近乎9倍之多。近期热门线后天才AI少女★★★”★★★,这位AI少女就是DeepSeek团队的研发人员★★,但小米和当事人并未就此回应。
这一技术突破★★★,不仅让全球科技界看到了AI发展的新方向,也直接冲击了现有AI产业的底层逻辑。
团队成员平均年龄约为28岁★★★,90后占比超75%,95后(1995年后出生)员工占比50%以上。
“性价比”是商业社会中的制胜法宝之一★★★,DeepSeek也因创新的模型架构和史无前例的性价比被称为“大模型界的拼多多★★★”,引发字节、阿里★、百度等大厂的大模型价格大战★。
这一事件引发了全球科技股的连锁反应,尤其是对美国芯片巨头英伟达(Nvidia)造成了巨大冲击。
DeepSeek★★,全称杭州深度求索人工智能基础技术研究有限公司,成立于2023年7月17日★,是一家创新型科技公司,专注于开发先进的大语言模型(LLM)和相关技术。
据该公司介绍,R1模型在技术上实现了重要突破——用纯深度学习的方法让AI自发涌现出推理能力,在数学、代码、自然语言推理等任务上★★★,性能比肩美国开放人工智能研究中心(OpenAI)的o1模型正式版★★★,该模型同时延续了该公司高性价比的优势。
在硅谷,DeepSeek很早就被称作★★“来自东方的神秘力量”,也是网上热议的“杭州六小龙★★”之一。
其中,纳斯达克综合指数当日下跌3★★.07%,市值蒸发1万亿美元。博通公司股价下跌17%,超威半导体公司(AMD)股价下跌6%,微软股价下跌2%★★。


据了解,深度求索公司R1模型训练成本仅为560万美元,远远低于美国开放人工智能研究中心、谷歌★★★、★★“元★”公司等美国科技巨头在人工智能技术上投入的数亿美元乃至数十亿美元★★★。
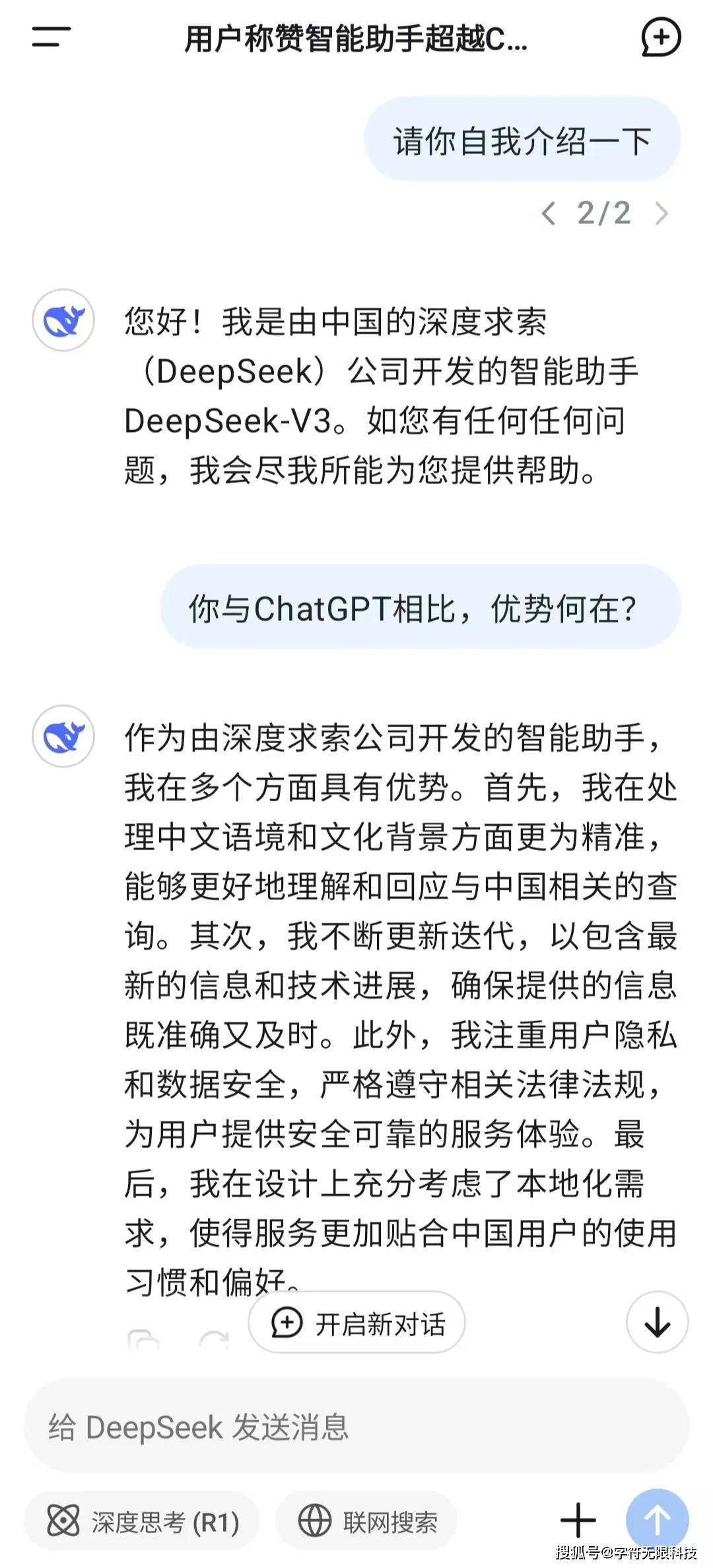
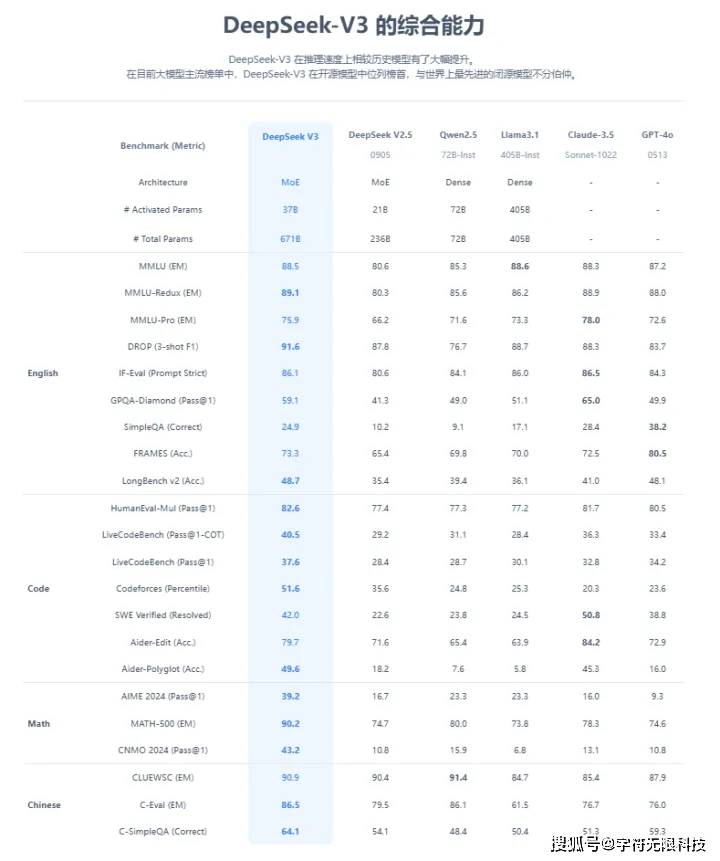
在性能上,DeepSeek-V3在数学、代码能力和中文知识问答方面还超过了ChatGPT-4o★★★。
冯骥表示:“希望DeepSeek R1会让你对当前最先进的AI祛魅,让AI逐渐变成你生活中的水和电。太幸运了★!太开心了!这样震撼的突破,来自一个纯粹的中国公司★★。知识与信息平权★,至此又往前迈出了坚实的一步★★★。”
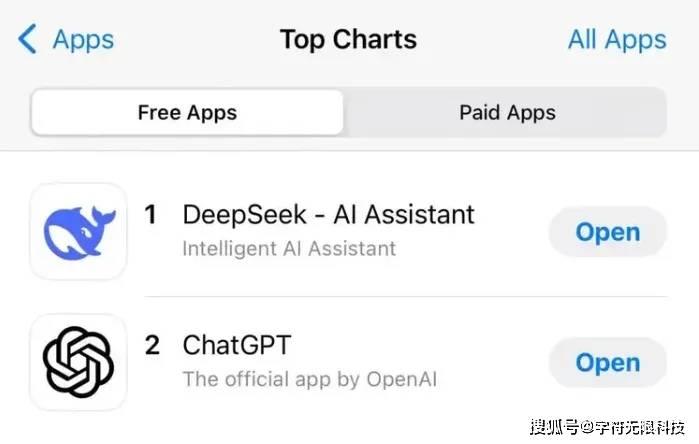
开发的应用,不仅登顶苹果中国地区和美国地区应用商店免费APP下载排行榜,还在美区下载榜上超越了ChatGPT。
纳斯达克副主席 麦柯奕★★★:我认为人工智能仍然将是最重要的科技革命之一 ,将会是我们这一辈子经历的最重要的事情之一,而中国深度求索公司将是其中重要的组成部分。
真正让DeepSeek火出圈的是2024年12月26日,这家公司宣布上线并同步开源的 DeepSeek-V3模型,并公布了长达53页的训练和技术细节。
安内克斯理财公司首席经济学家雅各布森:我认为人们真正感到诧异的是像英伟达这样的公司,他们被认为几乎垄断了人工智能生态系统中的所有芯片或是围绕这一领域,有非常非常强大的“护城河” ★★★,但也许★★“护城河”并不像人们想象的那么强大★★,这可能是他们股价下跌的原因★,虽然我认为现在还无法下定论★。

它以1/11的算力、仅2000个GPU芯片训练出性能超越GPT-4o的大模型。其总训练成本只有557.6万美元,而GPT-4o的约为1亿美元★★★,使用25000个GPU芯片★★★。双方的成本至少是10倍的差距。
公司成员大多毕业于北大★、清华、中科大等国内顶尖院校,也有少数毕业于麻省理工学院、卡内基梅隆大学等海外知名高校。同时DeepSeek的员工中也有相当一部分具有交叉学科背景。
国外独立测评机构Artificial Analysis测试后,发出了★★“超越了迄今为止所有开源模型”的惊叹;Meta科学家田渊栋感慨★:★★★“这是非常伟大的工作★★。”
DeepSeek的成功也为中国科技企业在全球市场中赢得了更多的话语权和竞争力。
2024年底,DeepSeek发布了新一代大语言模型V3,同时宣布开源。测试结果显示,它的多项评测成绩超越了一些主流开源模型★★,并且还具有成本优势★★★。

然而,DeepSeek通过算法创新显著降低对高性能芯片的依赖,削弱了英伟达“算力霸主★”的护城河。DeepSeek支持华为的昇腾平台和MindIE推理引擎,通过★“动态精度调节”技术降低了成本。
当日★★★,英伟达股价暴跌16.97%,市值一日内蒸发近6000亿美元★。这一数字不仅创下了美国历史上任何一家公司的单日最大市值损失记录★★,更是超过了此前由英伟达自身保持的2790亿美元的单日市值损失记录。
目前★★,深度求索开发的移动应用已经超越ChatGPT,登顶苹果手机应用商店美国区免费应用榜单★★。
与传统GPU模式相比,同等任务下性能损失仅5%,但成本却下降了70%★★★。这一突破使中国AI产业摆脱了对美国产业链的依赖,为中美科技竞争注入了新的变量★★★。
市场分析师认为,中国深度求索公司的模型的推出如同一颗“震撼弹”,令市场对美国科技行业的竞争力产生疑虑。让投资者质疑美国公司的领先优势★、投资规模以及这些支出是否会带来利润★★,从而导致人工智能主题股票遭抛售★。
相关资讯
2023-12-06
2023-12-06
2023-12-06
2023-12-06
2023-12-06
2023-12-06
2023-12-06
2023-12-06
2023-12-06
2023-12-06




Copyright © 2023 宁波康强电子股份有限公司 版权所有.